
{kind=link}
Data Engineering in Action: Airbnb’s Approach to Smarter Decision-Making
“We are surrounded by data, but starved for insights.” This observation by Jay Baer, a renowned CX expert, highlights a key challenge of our time. Despite the abundance of data today, it’s often not utilized to its full potential. A significant gap remains between data availability and actionable insights, often due to inadequate handling, processing, and analysis. However, data engineering has emerged as a preferred channel to overcome this challenge. By providing systems and workflows designed for efficient data handling and processing, it has redefined how organizations use their data.
This blog will explore how data engineering enables organizations to unlock the true value of their data with meaningful insights.
Understanding Data Engineering
Data engineering caters to the technical aspects and infrastructure requirements of processing data. It involves designing, building, and maintaining systems that gather, store, and analyze large volumes of data. Consequently, its key components include:
- Data Collection/Ingestion: Collecting and consolidating data from various sources such as databases, APIs, and real-time streams
- Data Processing: Correcting the issues & discrepancies and validating data to ensure it is accurate
- Data Storage: In databases, data warehouses, data lakes, or cloud storage solutions
- Data Integration: Combining this data into a cohesive system that provides a unified view for analysis.
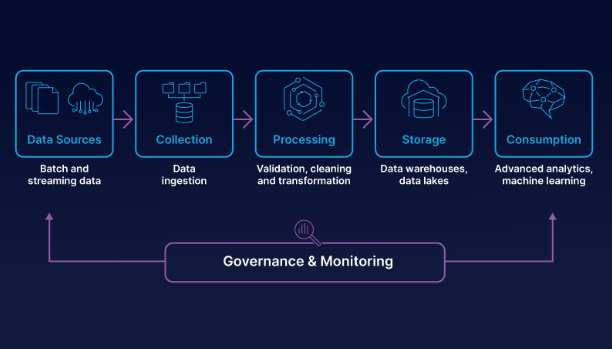
The above falls under ETL (Extract, Transform, Load), the process that extracts data from various sources, transforms it into a usable format, and loads it into a storage system.
It is also possible to create automated workflows that handle the movement and processing of data. Tools like Apache Airflow are used to schedule and monitor these data workflows.
How Data Engineering Drives Better Decision-Making
Many companies have started prioritizing data engineering, causing the market to grow from US$ 29.50 billion to US$ 77.37 billion in 2023, exhibiting a modest CAGR of 17.6%. (Source)
This growth has been attributed to the following data engineering benefits:
-
Enhancing Data Accuracy
Data engineering focuses on three main areas to improve accuracy: validation, error handling, and deduplication. By implementing pre-determined rules and quality checks during the ETL process, data engineering workflows verify that data is correct and within the expected ranges. It facilitates error handling by designing systems with inherent error detection and correction capabilities. Moreover, data engineering workflows also remove duplicate entries to maintain a single, accurate source of truth.
-
Improving Data Accessibility
Data engineering workflows also focus on making data accessible. This is done by storing it in a centralized repository (warehouse or lake). Once data from various sources is consolidated, indexing and partitioning strategies can be implemented to expedite data retrieval and improve query performance. To expand accessibility across more applications and systems, the data engineering pipelines can be augmented by API integrations.
-
Ease of Scaling
One of the most significant data engineering benefits is the ease of scaling. As businesses grow, so does the volume of data they generate and gather. Data engineering workflows are designed keeping in mind these increasing data requirements without compromising on the output quality. Often, for efficient data engineering, scalable cloud storage solutions like Amazon S3 or Google Cloud Storage are utilized. These distributed computing frameworks process large datasets across multiple machines, ensuring efficient data handling.
More accurate, accessible, and scalable data management empowers organizations to enhance data-driven decision-making. This capability fosters informed choices, leading to improved business outcomes and positioning the organizations for sustained success.
Common Challenges and Some Data Engineering Best Practices to Overcome them
- Data Integration: Integrating data from numerous sources with different formats and structures is a complex task. The source may be a database, API file, or some real-time data stream.
Automating the process via robust ETL pipelines can help you streamline the process. Alternatively, you can outsource data migration services for hassle-free data transfers with minimal downtime.
- Data Quality and Consistency: Ensuring the accuracy and consistency of data is crucial for comprehensive data analysis and probably one of the most significant challenges.
Integrating your ETL pipelines with data validation and cleaning processes can help you maintain quality without taking any additional processing time.
2. Data Security and Privacy: Protecting data from unauthorized access and ensuring compliance with data privacy regulations is a significant challenge. Breaches and non-compliance can have severe legal and financial consequences.
Implementing TLS/SSL, encryption, and authentication protocols, along with conducting frequent audits, can help establish robust governance frameworks and mitigate these risks.
3. Managing Complex Workflows: Data engineering is a comprehensive process with numerous complex workflows that have interdependent tasks. Ensuring they all run smoothly is challenging.
As seen above, orchestration tools like Airflow can help you schedule, monitor, and manage multiple data pipelines efficiently.
4. Keeping Pace with Technological Changes: Data engineering is an evolving field, and keeping up with emerging tools and technologies can be overwhelming.
Staying engaged in data engineering communities, such as IEEE, and participating in forums, conferences, and courses can help you stay updated on recent developments. Additionally, collaborating with a data engineering service provider can offer efficient, long-term knowledge transfer and assistance.
Airbnb is one such company that leveraged advanced data engineering to address the challenges above and build a scalable data infrastructure. Let’s explore how they developed it.
Strategic Data Engineering in Action: How Airbnb Developed a Scalable Data Infrastructure
As Airbnb grew from a small-scale startup into a globally known hospitality leader, the volume and complexity of its data increased significantly. The platform was receiving millions of listings across multiple regions, countless user reviews, transaction records, etc. Consequently, the company was:
- Struggling to keep up with the influx of massive volumes of data in diverse formats
- Caught up in data silos scattered across different systems and departments
- Facing data inaccuracy and inconsistency challenges
- Having lesser insights into their operations
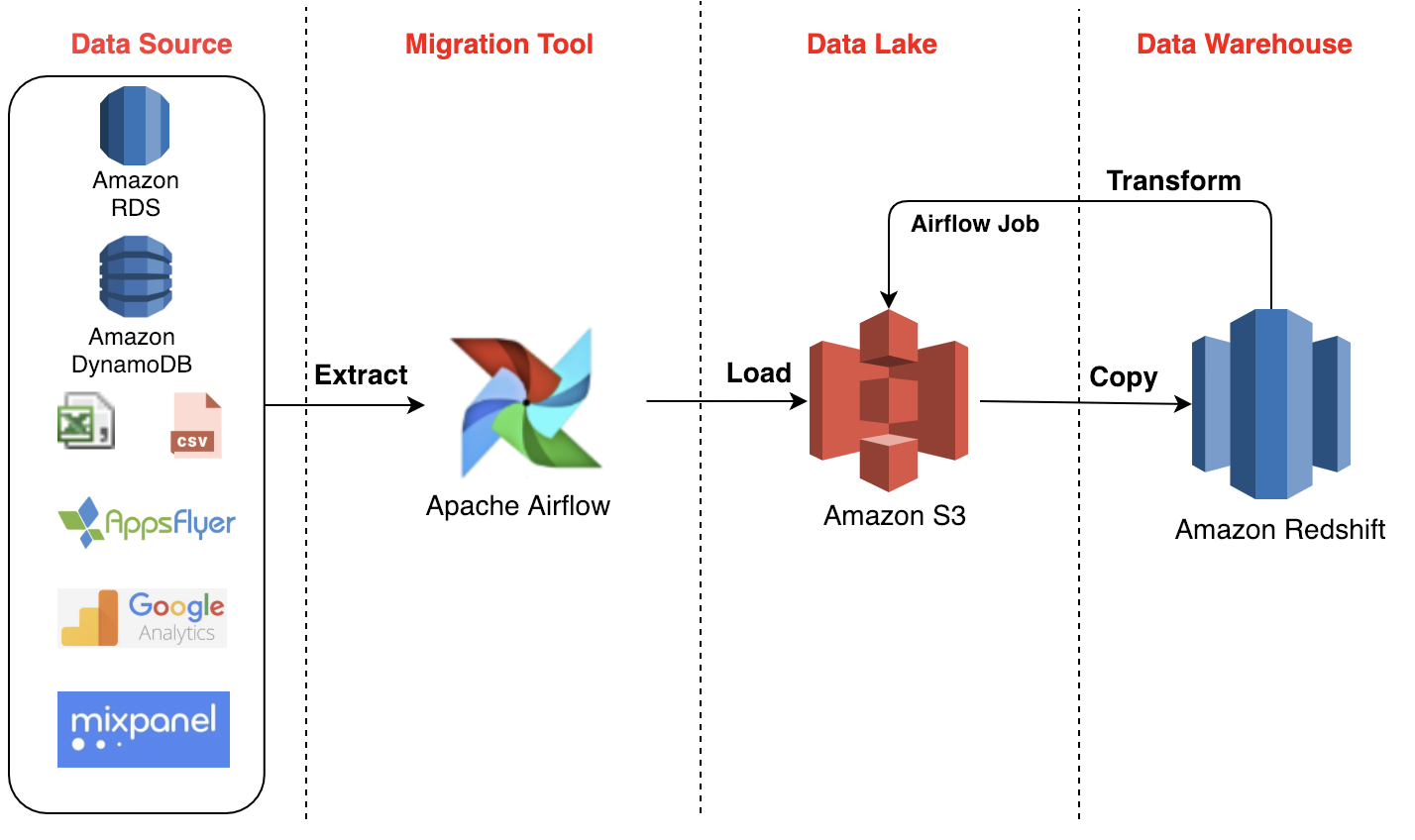
To address these challenges, Maxime Beauchemin, a reputed data engineer at Airbnb, developed “Airflow.” This state-of-the-art infrastructure is an open-source platform for developing, scheduling, and monitoring data engineering workflows.
{kind=link}
How Airflow Improved their Decision-Making with Data Engineering
| Challenge | How Airflow’s Data Engineering Capabilities Solved it |
| Influx of Massive Data Volumes | Airflow’s scalable and flexible architecture provided a framework that could easily handle increasing data volumes. Its parallel processing capabilities also enabled data engineers to process numerous datasets simultaneously, reducing overall processing time. Moreover, Airflow automated the ingestion and processing of data promptly. |
| Data Silos across Different Systems and Departments | With Airflow, data engineers created a unified data pipeline to integrate data from multiple sources into a centralized repository. These pipelines helped in breaking down data silos and enabled a holistic view. Additionally, Airflow’s framework made it easier to manage and orchestrate data workflows as needed. This provided additional consistency in ETL processes. |
| Data Inaccuracies and Inconsistencies | Airflow was designed with incorporated data validation and verification mechanisms within its workflows. This ensured data was properly cleaned and processed before being loaded into the centralized repository. |
| Lesser Insights into their Operations | Airflow’s ability to handle both batch and stream processing set the stage for data-driven decision-making in real-time. Additionally, Airflow is highly integrated with various data visualization tools, allowing the company to create custom dashboards for deeper operational insights. |
Emerging Trends and Developments in Data Engineering
The data engineering segment is growing, with certain key trends and developments at the forefront.
Emphasis on Data Observability
As the name suggests, data observability is about monitoring your data infrastructure. This market is rapidly growing; projections estimate it will reach up to $4.1 billion by 2028. With new tools and technologies emerging constantly, monitoring and understanding data pipelines is becoming increasingly easier. You can expect to see even more advancements in data observability soon. (Source)
AI and ML Integration
AI and ML integrations are making significant strides in data engineering. The AI data management market is projected to reach $70.2 billion by 2028. While it’s challenging to quantify AI’s direct impact on data engineering, its role in automating data processing and transfer is undeniable. In the coming years, expect more sophisticated utilization of AI and ML-powered data engineering pipelines, transforming how data is handled and analyzed. (Source)
Edge Computing
By processing data closer to where it’s generated (near the edge of the network), edge computing has started surpassing serverless and many others. This approach significantly reduces latency and bandwidth usage, making it easier to make split-second decisions through real-time updates. It has significantly grown from US$ 21.8 billion to US$ 60 billion (as expected by 2024). (Source)
DataOps
DataOps is a relatively new development emphasizing collaboration and automation across the entire data lifecycle. It is a strategic approach that bridges the gaps between data engineers, analysts, and operations teams. While the DataOps market is still nascent, it’s expected to grow up to US$ 11 billion by 2028. (Source)
Final Thoughts
Data engineering is no longer just an evolving data segment but has transitioned into a driving force behind business success. It has become fundamental to data-driven decision-making, allowing organizations to process and analyze it in real time. Looking ahead, this practice is poised to become more sophisticated and integral to long-term organizational success. Advancements and innovations like AI will continue to refine these processes, making businesses more responsive to sudden changes. To stay competitive in this data-driven world, you must be open to these innovations. Partnering with professional data engineering service providers can also be a strategic move, ensuring your data operations are optimized and in sync with the latest technological advancements.